
Artificial intelligence (AI), particularly deep learning models, are often considered black boxes because their decision-making processes remain difficult to interpret. These models can accurately identify objects—such as recognizing a bird in a photo—but understanding exactly how they arrive at these conclusions is a significant challenge. Until now, most interpretability efforts have focused on analyzing the internal structures of the models themselves.
New approach to AI interpretability
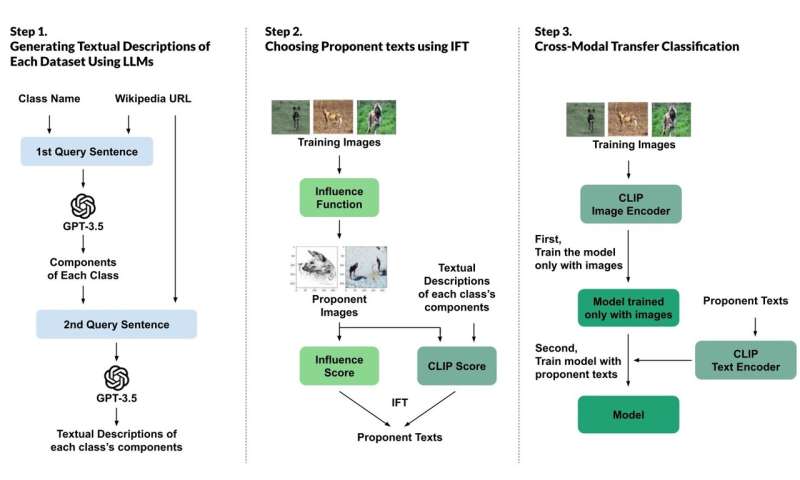
A research team affiliated with UNIST has taken a different approach. Led by Professor Tae-hwan Kim from the UNIST Graduate School of Artificial Intelligence, the team have developed a novel method to clarify how AI models learn by translating the training data into human-readable descriptions. This approach aims to shed light on the data that forms the foundation of AI learning, making it more transparent and understandable.
While traditional explainable AI (XAI) research examines a model's predictions or internal calculations after training, this study takes a different route. It aims to make the data itself transparent—by characterizing data through descriptive language—so we can better understand how AI learns and makes decisions.
Generating and evaluating data descriptions
The researchers utilized large language models, such as ChatGPT, to generate detailed descriptions of objects within images. To ensure the descriptions were accurate and reliable, they incorporated external knowledge sources, like online encyclopedias.
However, not all generated descriptions are equally useful for training AI models. In order to identify the most relevant ones, the team devised a new metric, called Influence scores for Texts (IFT). This score assesses two key aspects: how much each description impacts the model's predictions—measured by the change in accuracy if that description is removed—and how well the description aligns with the visual content, evaluated through CLIP scores.
For example, in a bird classification task, descriptions that focus on bill shape or feather patterns with high IFT scores indicate that the model has learned to recognize birds based on these characteristics, rather than irrelevant details, such as background color.
Testing the impact of explanations
To verify whether these influential descriptions actually enhance model performance, the team conducted cross-model transfer experiments. They trained models using only high-IFT descriptions and tested their accuracy across multiple datasets. The results demonstrated that models trained with these carefully selected explanations were more stable and achieved higher accuracy, confirming the meaningful contribution of the explanations to the learning process.
Professor Kim commented, "Allowing AI to explain its training data in human-understandable terms offers a promising way to reveal how deep learning models make decisions. It's a significant step toward more transparent and trustworthy AI systems."
This research was accepted for presentation at EMNLP 2025.
More information: Chaeri Kim et al, Data Descriptions from Large Language Models with Influence Estimation, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (2025). DOI: 10.18653/v1/2025.emnlp-main.1717
Provided by UNIST
Citation: Decoding black box AI with human-readable data descriptions and influence (2026, January 8) retrieved 9 January 2026 from https://techxplore.com/news/2026-01-decoding-black-ai-human-readable.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no part may be reproduced without the written permission. The content is provided for information purposes only.